
Data Strategy Component: Provision
This blog is the 2nd in a series focused on reviewing the individual Components of a Data Strategy. This edition discusses the concept of data provisioning and the various details of making data sharable.
The definition of Provision is:
“Supplying data in a sharable form while respecting all rules and access guidelines”
One of the biggest frustrations that I have in the world of data is that few organizations have established data sharing as a responsibility. Even fewer have setup the data to be ready to share and use by others. It’s not uncommon for a database programmer or report developer to have to retrieve data from a dozen different systems to obtain the data they need. And, the data arrives in different formats and files that change regularly. This lack of consistency generates large ongoing maintenance costs and requires an inordinate amount of developer time to re-transform, prepare, fix data to be used (numerous studies have found that ongoing source data maintenance can take as much of 50% of the database developers time after the initial programming effort is completed).
Should a user have to know the details (or idiosyncrasies) of the application system that created the data to use the data? (That’s like expecting someone to understand the farming of tomatoes and manufacturing process of ketchup in order to be able to put ketchup on their hamburger). The idea of Provision is to establish the necessary rigor to simplify the sharing of data.
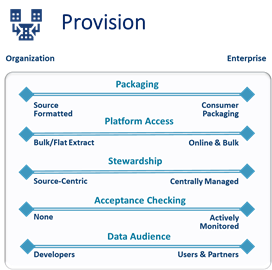
I’ve identified 5 of the most common facets of data sharing in the illustration above – there are others. As a reminder (from last week’s blog), each facet should be considered individually. And because your Data Strategy goals will focus on future aspirational goals as well as current needs, you’ll likely to want to review the different options for each facet. Each facet can target a small organization’s issues or expand to address a diverse enterprise’s needs.
Packaging
This is the most obvious aspect of provisioning: structuring and formatting the data in a clear and understandable manner to the data consumer. All too often data is packaged at the convenience of the developer instead of the convenience of the user. So, instead of sharing data as a backup file generated by an application utility in a proprietary (or binary) format, the data should be formatted so every field is labeled and formatted (text, XML) for a non-technical user to access using easily available tools. The data should also be accompanied with metadata to simplify access.
Platform Access
This facet works with Packaging and addresses the details associated with the data container. Data can be shared via a file, a database table, an API, or one of several other methods. While sharing data in a programmer generated file is better than nothing, a more effective approach would be to deliver data in a well-known file format (such as Excel) or within a table contained in an easily accessible database (e.g. data lake or data warehouse).
Stewardship
Source data stewardship is critical in the sharing of data. In this context, a Source Data Steward is someone that is responsible for supporting and maintaining the shared data content (there several different types of data stewards). In some companies, there’s a data steward responsible for the data originating from an individual source system. Some companies (focused on sharing enterprise-level content) have positioned data stewards to support individual subject areas. Regardless of the model used, the data steward tracks and communicates source data changes, monitors and maintains the shared content, and addresses support needs. This particular role is vital if your organization is undertaking any sort of data self-service initiative.
Acceptance Checking
This item addresses the issues that are common in the world of electronic data sharing: inconsistency, change, and error. Acceptance checking is a quality control process that reviews the data prior to distribution to confirm that it matches a set of criteria to ensure that all downstream users receive content as they expect. This item is likely the easiest of all details to implement given the power of existing data quality and data profiling tools. Unfortunately, it rarely receives attention because of most organization’s limited experience with data quality technology.
Data Audience
In order to succeed in any sort of data sharing initiative, whether in supporting other developers or an enterprise data self-service initiative, it’s important to identify the audience that will be supported. This is often the facet to consider first, and it’s valuable to align the audience with the timeframe of data sharing support. It’s fairly common to focus on delivering data sharing for developers support first followed by technical users and then the large audience of business users.
In the era of “data is a business asset” , data sharing isn’t a courtesy, it’s an obligation. Data sharing shouldn’t occur at the convenience of the data producer, it should be packaged and made available for the ease of the user.

Trackbacks / Pingbacks