
Data Strategy Component: Assemble
This blog is 4th in a series focused on reviewing the individual Components of a Data Strategy. This edition discusses the component Assemble and the numerous details involved with sourcing, cleansing, standardizing, preparing, integrating, and moving the data to make it ready to use.
The definition of Assemble is:
“Cleansing, standardizing, combining, and moving data residing in multiple locations and producing a unified view”
In the Data Strategy context, Assemble includes all of the activities required to transform data from its host-oriented application context to one that is “ready to use” and understandable by other systems, applications, and users.
Most data used within our companies is generated from the applications that run the company (point-of-sale, inventory management, HR systems, accounting) . While these applications generate lots of data, their focus is on executing specific business functions; they don’t exist to provide data to other systems. Consequently, the data that is generated is “raw” in form; the data reflects the specific aspects of the application (or system of origin). This often means that the data hasn’t been standardized, cleansed, or even checked for accuracy. Assemble is all of the work necessary to convert data from a “raw” state to one that is ready for business usage.
I’ve identified 5 facets to consider when developing your Data Strategy that are commonly employed to make data “ready to use”. As a reminder (from the initial Data Strategy Component blog), each facet should be considered individually. And because your Data Strategy goals will focus on future aspirational goals as well as current needs, you’ll likely want to consider different options for each. Each facet can target a small organization’s issues or expand to focus on a large company’s diverse needs.
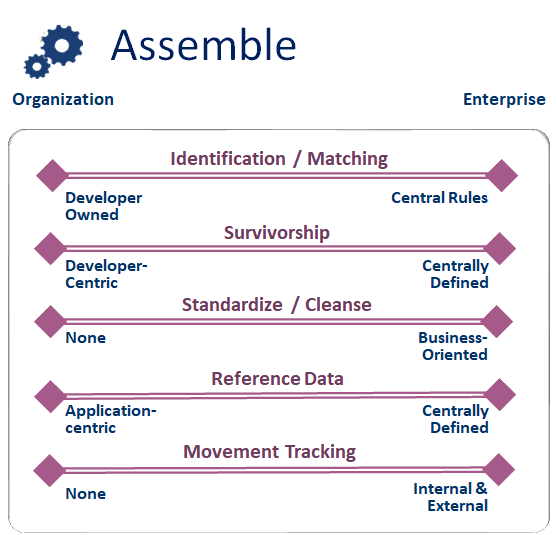
Identification and Matching
Data integration is one of the most prevalent data activities occurring within a company; it’s a basic activity employed by developers and users alike. In order to integrate data from multiple sources, it’s necessary to determine the identification values (or keys) from each source (e.g. the employee id in an employee list, the part number in a parts list). The idea of matching is aligning data from different sources with the same identification values. While numeric values are easy to identify and match (using the “=” operator), character-based values can be more complex (due to spelling irregularities, synonyms, and mistakes).
Even though it’s highly tactical, Identification and matching is important to consider within a Data Strategy to ensure that data integration is processed consistently. And one of the (main) reasons that data variances continue to exist within companies (despite their investments in platforms, tools, and repositories) is because the need for standardized Identification and Matching has not been addressed.
Survivorship
Survivorship is a pretty basic concept: the selection of the values to retain (or survive) from the different sources that are merged. Survivorship rules are often unique for each data integration process and typically determined by the developer. In the context of a data strategy, it’s important to identify the “systems of reference” because the identification of these systems provide clarity to developers and users to understand which data elements to retain when integrating data from multiple systems.
Standardize / Cleanse
The premise of data standardization and cleansing is to identify inaccurate data and correct and reformat the data to match the requirements (or the defined standards) for a specific business element. This is likely the single most beneficial process to improve the business value (and the usability) of data. The most common challenge to data standardization and cleansing is that it can be difficult to define the requirements. The other challenge is that most users aren’t aware that their company’s data isn’t standardized and cleansed as a matter of practice. Even though most companies have multiple tools to cleanup addresses, standardize descriptive details, and check the accuracy of values, the use of these tools is not common.
Reference Data
Wikipedia defines reference data as data that is used to classify or categorize other data. In the context of a data strategy, reference data is important because it ensures the consistency of data usage and meaning across different systems and business areas. Successful reference data means that details are consistently identified, represented, and formatted the same way across all aspects of the company (if the color of a widget is “RED”, then the value is represented as “RED” everywhere – not “R” in product information system, 0xFF0000 in inventory system, and 0xED2939 in product catalog). A Reference Data initiative is often aligned with a company’s data strategy initiative because of its impact to data sharing and reuse.
Movement Tracking
The idea of movement is to record the different systems that a data element touches as it travels (and is processed) after the data element is created. Movement tracking (or data lineage) is quite important when the validity and accuracy of a particular data value is questioned. And in the current era of heightened consumer data privacy and protection, the need for data lineage and tracking of consumer data within a company is becoming a requirement (and it’s the law in California and the European Union).
The dramatic increase in the quantity and diversity of data sources within most companies over the past few years has challenged even the most technology advanced organizations. It’s not uncommon to find one of the most visible areas of user frustration to be associated with accessing new (or additional) data sources. Much of this frustration occurs because of the challenge in sourcing, integrating, cleansing, and standardizing new data content to be shared with users. As is the case with all of the other components, the details are easy to understand, but complex to implement. A company’s data strategy has to evolve and change when data sharing becomes a production business requirement and users want data that is “ready to use”.
The 5 Components of a Data Strategy

Because the idea of building a data strategy is a fairly new concept in the world of business and information technology (IT), there’s a fair amount of discussion about the pieces and parts that comprise a Data Strategy. Most IT organizations have invested heavily in developing plans to address platforms, tools, and even storage. Those IT plans are critical in managing systems and capturing and retaining content generated by a company’s production applications. Unfortunately, those details don’t typically address all of the data activities that occur after an application has created and processed data from the initial business process. The reasons that folks take on the task of developing a Data Strategy is because of the challenges in finding, identifying, sharing, and using data. In any company, there are numerous roles and activities involved in delivering data to support business processing and analysis. A successful Data Strategy must support the breadth of activities necessary to ensure that data is “ready to use”.
There are five core components in a data strategy that work together as building blocks to address the various details necessary to comprehensively support the management and usage of data.
Identify The ability to identify data and understand its meaning regardless of its structure, origin, or location.
This concept is pretty obvious, but it’s likely one of the biggest obstacles in data usage and sharing. All too often, companies have multiple and different terms for specific business details (customer: account, client, patron; income: earnings, margin, profit). In order to analyze, report, or use data, people need to understand what it’s called and how to identify it. Another aspect of Identify is establishing the representation of the data’s value (Are the company’s geographic locations represented by name, number, or an abbreviation?) A successful Data Strategy would identify the gaps and needs in this area and identify the necessary activities and artifacts required to standardize data identification and representation.
Provision Enabling data to be packaged and made available while respecting all rules and access guidelines.
Data is often shared or made available to others at the convenience of the source system’s developers. The data is often accessible via database queries or as a series of files. There’s rarely any uniformity across systems or subject areas, and usage requires programming level skills to analyze and inventory the contents of the various tables or files. Unfortunately, the typical business person requiring data is unlikely to possess sophisticated programming and data manipulation skills. They don’t want raw data (that reflects source system formats and inaccuracies), they want data that is uniformly formatted and documented that is ready to be added to their analysis activities.
The idea of Provision is to package and provide data that is “ready to use”. A successful Data Strategy would identify the various data sharing needs and identify the necessary methods, practices, and tooling required to standardize data packaging and sharing.
Store Persisting data in a structure and location that supports access and processing across the enterprise.
Most IT organizations have solid plans for addressing this area of a Data Strategy. It’s fairly common for most companies to have a well-defined set of methods to determine the platform where online data is stored and processed, how data is archived for disaster recovery, and all of the other details such as protection, retention, and monitoring.
As the technology world has evolved, there are other facets of this area that require attention. The considerations include managing data distributed across multiple locations (the cloud, premise systems, and even multiple desktops), privacy and protection, and managing the proliferation of copies. With the emergence of new consumer privacy laws, it’s risky to store multiple copies of data, and it’s become necessary to track all existing copies of content. A successful Data Strategy ensures that any created data is always available for future access without requiring everyone to create their own copy.
Assemble Standardizing, combining, and moving data residing in multiple locations and providing a unified view.
It’s no secret that data integration is one of the more costly activities occurring within an IT organization; nearly 40% of the cost of new development is consumed by data integration activities. And Assemble isn’t limited to integration, it also includes correcting, standardizing, and formatting the content to make it “ready to use”.
With the growth of analytics and desktop decisioning making, the need to continually analyze and include new data sets into the decision-making process has exploded. Processing (or preparing or wrangling) data is no longer confined to the domain of the IT organization, it has become an end user activity. A successful Data Strategy had to ensure that all users can be self-sufficient in their abilities to process data.
Govern Establishing and communicating information rules, policies, and mechanisms to ensure effective data usage.
While most organizations are quick to identify their data as a core business asset, few have put the necessary rigor in place to effectively manage data. Data Governance is about establishing rules, policies, and decision mechanisms to allow individuals to share and use data in a manner that respects the various (legal and usage) guidelines associated with that data. The inevitable challenge with Data Governance is adoption by the entire data supply chain – from application developers to report developers to end users. Data Governance isn’t a user-oriented concept, it’s a data-oriented concept. A successful Data Strategy identifies the rigor necessary to ensure a core business asset is managed and used correctly.
The 5 Components of a Data Strategy is a framework to ensure that all of a company’s data usage details are captured and organized and that nothing is unknowingly overlooked. A successful Data Strategy isn’t about identifying every potential activity across the 5 different components. It’s about making sure that all of the identified solutions to the problems in accessing, sharing, and using data are reviewed and addressed in a thorough manner.
Do You Need A Data Strategy?

During my time teaching Data Strategy in the class room, I’m frequently asked the question, “how do I know if I need a data strategy?” For those of you that are deep thinkers, business strategists, or even data architects, I suspect your answer is either “yes!” or “why not?”.
When I’m asked that question, I actually think there’s a different question at hand, “Should I invest the time in developing a data strategy instead of something else?”
In today’s business world, there’s not a shortage of “to do list” items. So, prioritizing the development of a Data Strategy means deprioritizing some other item. In order to understand the relative priority and benefit of a Data Strategy initiative, take a look at the need, pain, or problem you’re addressing along with the quantity of people affected. Your focus should be understanding how a Data Strategy initiative will benefit the team members’ ability to do their job.
To get started, I usually spend time up front interviewing folks to understand the strengths, weaknesses, challenges, and opportunities that exist with data within a company (or organization). Let me share 5 questions that I always ask.
- Is the number of users (or organizations) building queries/reports to analyze data growing?
- Are there multiple reports containing conflicting information?
- Can a new staff member find and use data on their own, or does it require weeks or months of staff mentoring?
- Is data systematically inspected for accuracy (and corrected)? Is anyone responsible for fixing “broken data”?
- Is anyone responsible for data sharing?
While you might think these questions are a bit esoteric, each one has a specific purpose. I’m a big fan of positioning any new strategy initiative to clearly identify the problems that are going to be solved. If you’re going to undertake the development of a Data Strategy, you want to make certain that you will improve staff members’ ability to make decisions and be more effective at their jobs. These questions will help you identify where people struggle getting the job done, or where there’s an unquantified risk with using data to make decisions.
So, let me offer an explanation of each question.
- “Is the number of users (or organizations) building queries/reports to analyze data growing”
The value of a strategy is directly proportional to the number of people that are going to be affected. In the instance of a data strategy, it’s valuable to understand the number of people that use data (hands-on) to make decisions or do their jobs. If the number is small or decreasing, a strategy initiative may not be worth the investment in time and effort. The larger the number, the greater the impact to the effectiveness (and productivity) to the various staff members.
- “Are there multiple reports containing conflicting information? “
If you have conflicting details within your company that means decisions are made with inaccurate data. That also means that there’s mistrust of information and team members are spending time confirming details. That’s business risk and a tremendous waste of time.
- “Can a new staff member find and use data…”
If a new staff member can’t be self-sufficient after a week or two on the job (when it comes to data access and usage), you have a problem. That’s like someone joining the company and not having access to office supplies, a parking space, and email. And, if the only way to learn is to beg for time for other team members – your spending time with two people not doing their job. It’s a problem that’s being ignored.
- “Is data systematically inspected for accuracy (and corrected)? …”
This item is screaming for attention. If you’re in a company that uses data to make decisions, and no one is responsible for inspecting the content, you have a problem. Think about this issue another way: would you purchase hamburger at the grocery store if there was a sign that stated “Never inspected. May be spoiled. Not our responsibility”?
- Is anyone responsible for data sharing?
This item gets little attention in most companies and is likely the most important of all the questions. If data is a necessary ingredient in decision making and there isn’t anyone actively responsible for ensuring that new data assets are captured, stored, tracked, managed, and shared, you’re saying that data isn’t a business asset. (How many assets in the company aren’t tied to someone’s responsibilities?)
If the answer to all of the questions is “no” – great. You’re in an environment where data is likely managed in a manner that supports a multitude of team members’ needs across different organizations. If you answered “yes” to a single question, it’s likely that an incremental investment in a tactical data management effort would be helpful. If more than 1 question is answered “yes”, your company (and the team) will benefit from a Data Strategy initiative.
Who Has My Personal Data?

In order to prepare for the cooking gauntlet that often occurs with the end of year holiday season, I decided to purchase a new rotisserie oven. The folks at Acme Rotisserie include a large amount of documentation with their rotisserie. I reviewed the entire pile and was a bit surprised by the warranty registration card. The initial few questions made sense: serial number, place of purchase, date of purchase, my home address. The other questions struck me as a bit too inquisitive: number of household occupants, household income, own/rent my residence, marital status, and education level. Obviously, this card was a Trojan horse of sorts; provide registration details –and all kinds of other personal information. They wanted me to give away my personal information so they could analyze it, sell it, and make money off of it.
Companies collecting and analyzing consumer data isn’t anything new –it’s been going on for decades. In fact, there are laws in place to protect consumer’s data in quite a few industries (healthcare, telecommunications, and financial services). Most of the laws focus on protecting the information that companies collect based on their relationship with you. It’s not the just details that you provide to them directly; it’s the information that they gather about how you behave and what you purchase. Most folks believe behavioral information is more valuable than the personal descriptive information you provide. The reason is simple: you can offer creative (and highly inaccurate) details about your income, your education level, and the car you drive. You can’t really lie about your behavior.
I’m a big fan of sharing my information if it can save me time, save me money, or generate some sort of benefit. I’m willing to share my waist size, shirt size, and color preferences with my personal shopper because I know they’ll contact me when suits or other clothing that I like is available at a good price. I’m fine with a grocer tracking my purchases because they’ll offer me personalized coupons for those products. I’m not okay with the grocer selling that information to my health insurer. Providing my information to a company to enhance our relationship is fine; providing my information to a company so they can share, sell, or otherwise unilaterally benefit from it is not fine. My data is proprietary and my intellectual property.
Clearly companies view consumer data to be a highly valuable asset. Unfortunately, we’ve created a situation where there’s little or no cost to retain, use, or abuse that information. As abuse and problems have occurred within certain industries (financial services, healthcare, and others), we’ve created legislation to force companies to responsibly invest in the management and protection of that information. They have to contact you to let you know they have your information and allow you to update communications and marketing options. It’s too bad that every company with your personal information isn’t required to behave in the same way. If data is so valuable that a company retains it, requiring some level of maintenance (and responsibility) shouldn’t be a big deal.
It’s really too bad that companies with copies of my personal information aren’t required to contact me to update and confirm the accuracy of all of my personal details. That would ensure that all of the specialized big data analytics that are being used to improve my purchase experiences were accurate. If I knew who had my data, I could make sure that my preferences were up to date and that the data was actually accurate.
It’s unfortunate that Acme Rotisserie isn’t required to contact me to confirm that I have 14 children, an advanced degree in swimming pool construction, and that I have Red Ferrari in my garage. It will certainly be interesting to see the personalized offers I receive for the upcoming Christmas shopping season.
Project Success = Data Usability

One of the challenges in delivering successful data-centric projects (e.g. analytics, BI, or reporting) is realizing that the definition of project success differs from traditional IT application projects. Success for a traditional application (or operational) project is often described in terms of transaction volumes, functional capabilities, processing conformance, and response time; data project success is often described in terms of business process analysis, decision enablement, or business situation measurement. To a business user, the success of a data-centric project is simple: data usability.
It seems that most folks respond to data usability issues by gravitating towards a discussion about data accuracy or data quality; I actually think the more appropriate discussion is data knowledge. I don’t think anyone would argue that to make data-enabled decisions, you need to have knowledge about the underlying data. The challenge is understanding what level of knowledge is necessary. If you ask a BI or Data Warehouse person, their answer almost always includes metadata, data lineage, and a data dictionary. If you ask a data mining person, they often just want specific attributes and their descriptions — they don’t care about anything else. All of these folks have different views of data usability and varying levels (and needs) for data knowledge.
One way to improve data usability is to target and differentiate the user audience based on their data knowledge needs. There are certainly lots of different approaches to categorizing users; in fact, every analyst firm and vendor has their own model to describe different audience segments. One of the problems with these types of models is that they tend to focus heavily on the tools or analytical methods (canned reports, drill down, etc.) and ignore the details of data content and complexity. The knowledge required to manipulate a single subject area (revenue or customer or usage) is significantly less than the skills required to manipulate data across 3 subject areas (revenue, customer, and usage). And what exacerbates data knowledge growth is the inevitable plethora of value gaps, inaccuracies, and inconsistencies associated with the data. Data knowledge isn’t just limited to understanding the data; it includes understanding how to work around all of the imperfections.
Here’s a model that categories and describes business users based on their views of data usability and their data knowledge needs
Level 1: “Can you explain these numbers to me?”
This person is the casual data user. They have access to a zillion reports that have been identified by their predecessors and they focus their effort on acting on the numbers they get. They’re not a data analyst – their focus is to understand the meaning of the details so they can do their job. They assume that the data has been checked, rechecked, and vetted by lots of folks in advance of their receiving the content. They believe the numbers and they act on what they see.
Level 2: “Give me the details”
This person has been using canned reports, understands all the basic details, and has graduated to using data to answer new questions that weren’t identified by their predecessors. They need detailed data and they want to reorganize the details to suit their specific needs (“I don’t want weekly revenue breakdowns – I want to compare weekday revenue to weekend revenue”). They realize the data is imperfect (and in most instances, they’ll live with it). They want the detail.
Level 3: “I don’t believe the data — please fix it”
These folks know their area of the business inside/out and they know the data. They scour and review the details to diagnose the business problems they’re analyzing. And when they find a data mistake or inaccuracy, they aren’t shy about raising their hand. Whether they’re a data analyst that uses SQL or a statistician with their favorite advanced analytics algorithms, they focus on identifying business anomalies. These folks are the power users that are incredibly valuable and often the most difficult for IT to please.
Level 4: “Give me more data”
This is subject area graduation. At this point, the user has become self-sufficient with their data and needs more content to address a new or more complex set of business analysis needs. Asking for more data – whether a new source or more detail – indicates that the person has exhausted their options in using the data they have available. When someone has the capacity to learn a new subject area or take on more detailed content, they’re illustrating a higher level of data knowledge.
One thing to consider about the above model is that a user will have varying data knowledge based on the individual subject area. A marketing person may be completely self-sufficient on revenue data but be a newbie with usage details. A customer support person may be an expert on customer data but only have limited knowledge of product data. You wouldn’t expect many folks (outside of IT) to be experts on all of the existing data subject areas. Their knowledge is going to reflect the breadth of their job responsibilities.
As someone grows and evolves in business expertise and influence, it’s only natural that their business information needs would grow and evolve too. In order to address data usability (and project success), maybe it makes sense to reconsider the various user audience categories and how they are defined. Growing data knowledge isn’t about making everyone data gurus; it’s about enabling staff members to become self-sufficient in their use of corporate data to do their jobs.
Photo “Ladder of Knowledge” courtesy of degreezero2000 via Flickr (Creative Commons license).
The Formula for Analytics Success: Data Knowledge

Companies spend a small fortune continually investing and reinvesting in making their business analysts self-sufficient with the latest and greatest analytical tools. Most companies have multiple project teams focused on delivering tools to simplify and improve business decision making. There are likely several standard tools deployed to support the various data analysis functions required across the enterprise: canned/batch reports, desktop ad hoc data analysis, and advanced analytics. There’s never a shortage of new and improved tools that guarantee simplified data exploration, quick response time, and greater data visualization options, Projects inevitably include the creation of dozens of prebuilt screens along with a training workshop to ensure that the users understand all of the new whiz bang features associated with the latest analytic tool incarnation. Unfortunately, the biggest challenge within any project isn’t getting users to master the various analytical functions; it’s ensuring the users understand the underlying data they’re analyzing.
If you take a look at the most prevalent issue with the adoption of a new business analysis tool is the users’ knowledge of the underlying data. This issue becomes visible with a number of common problems: the misuse of report data, the misunderstanding of business terminology, and/or the exaggeration of inaccurate data. Once the credibility or usability of the data comes under scrutiny, the project typically goes into “red alert” and requires immediate attention. If ignored, the business tool quickly becomes shelfware because no one is willing to take a chance on making business decisions based on risky information.
All too often the focus on end user training is tool training, not data training. What typically happens is that an analyst is introduced to the company’s standard analytics tool through a “drink from a fire hose” training workshop. All of the examples use generic sales or HR data to illustrate the tool’s strengths in folding, spindling, and manipulating the data. And this is where the problem begins: the vendor’s workshop data is perfect. There’s no missing or inaccurate data and all of the data is clearly labeled and defined; classes run smoothly, but it just isn’t reality Somehow the person with no hands-on data experience is supposed to figure out how to use their own (imperfect) data. It’s like someone taking their first ski lesson on a cleanly groomed beginner hill and then taking them up to the top of an a black diamond (advanced) run with step hills and moguls. The person works hard but isn’t equipped to deal with the challenges of the real world. So, they give up on the tool and tell others that the solution isn’t usable.
All of the advanced tools and manipulation capabilities don’t do any good if the users don’t understand the data. There are lots of approaches to educating users on data. Some prefer to take a bottom-up approach (reviewing individual table and column names, meanings, and values) while others want to take a top-down approach (reviewing subject area details, the associated reports, and then getting into the data details). There are certainly benefits of one approach over the other (depending on your audience); however, it’s important not to lose sight of the ultimate goal: giving the users the fundamental data knowledge they need to make decisions. The fundamentals that most users need to understand their data include a review of
- the business subject area associated with their dat
- business terms, definitions, and their associated data attributes
- data values and their representations
- business rules and calculations associated with the individual values
- the data’s origin (a summary of the business processes and source system)
The above details may seem a bit overwhelming if you consider that most companies have mature reporting environments and multi-terabyte data warehouses. However, we’re not talking about training someone to be an expert on 1000 data attributes contained within your data warehouse; we’re talking about ensuring someone’s ability to use an initial set of reports or a new tool without requiring 1-on-1 training. It’s important to realize that the folks with the greatest need for support and data knowledge are the newbies, not the experienced folks.
There are lots of options for imparting data knowledge to business users: a hands-on data workshop, a set of screen videos showing data usage examples, or a simple set of web pages containing definitions, textual descriptions, and screen shots. Don’t get wrapped up in the complexities of creating the perfect solution – keep it simple. I worked with a client that deployed their information using a set of pages constructed with PowerPoint that folks could reference in a the company’s intranet. If your users have nothing – don’t’ worry about the perfect solution – give them something to start with that’s easy to use.
Remember that the goal is to build users’ data knowledge that is sufficient to get them to adopt and use the company’s analysis tools. We’re not attempting to convert everyone into data scientists; we just want them to use the tools without requiring 1-on-1 training to explain every report or data element.
Photo courtesy of NASA. Nasa Ames Research Center engineer H Julian “Harvey” Allen illustrating data knowledge (relating to capsule design for the Mercury program)
Data Governance: Managing Data as an Asset
 I always find it interesting when people pile onto the company’s latest and most popular project or initiative. People love to gravitate to whatever is new and sexy within the company, regardless of what they’re working on or their current responsibilities. There never seems to be a shortage of the “bright shiny object” syndrome – you know, organizational ADHD. This desire to jump on the band wagon often positions individuals with limited experience to own and drive activities they don’t fully understand. The world of data governance is rife with supporters and promoters that are thrilled to be involved, but a bit unprepared to participate and execute. It’s like loading a gun and pulling the trigger before aiming – you’ll make a lot of noise and likely miss the target. If only folks spent a bit of time educating others about the meaning and purpose of data governance before they got started.
I always find it interesting when people pile onto the company’s latest and most popular project or initiative. People love to gravitate to whatever is new and sexy within the company, regardless of what they’re working on or their current responsibilities. There never seems to be a shortage of the “bright shiny object” syndrome – you know, organizational ADHD. This desire to jump on the band wagon often positions individuals with limited experience to own and drive activities they don’t fully understand. The world of data governance is rife with supporters and promoters that are thrilled to be involved, but a bit unprepared to participate and execute. It’s like loading a gun and pulling the trigger before aiming – you’ll make a lot of noise and likely miss the target. If only folks spent a bit of time educating others about the meaning and purpose of data governance before they got started.
Let me first offer up some definitions from a few reputable sources…
“Data governance is a set of processes that ensures that important data assets are formally managed throughout the enterprise” (Wikipedia)
“The process by which an organization formalizes the ‘fiduciary duty’ for the management of data assets” (Forrester Research)
“…the overall management of the availability, usability, integrity, and security of the data employed in an enterprise” (TechTarget)
For those of you that have experience with data governance, the above definitions are unlikely to be much of a surprise. For the other 99%, there’s likely to be some head scratching. I actually think most folks that haven’t been indoctrinated to the religion of data have just assumed that data governance is simply a new incarnation of yesterday’s data quality or metadata discussion. That probably shouldn’t be much of a surprise; the discussion of data inaccuracy and data dictionaries has gotten so much air time over the past 30 years, the typical business user probably feels brainwashed when they hear anything with “data” in the title. I actually think that Data Governance may win the prize for being among the most misunderstood concepts within Information Technology.
Data governance is a very simple concept. Data Governance is about establishing the processes for accessing and sharing data and resolving conflict when the processes don’t work.
A Data Governance initiative is really about instilling the concept of managing data as a corporate asset. Companies have standard methods and processes for asset management: your Procurement group has a slew of rules and processes to support the purchasing of office supplies; the HR organization has rules and guidelines for hiring and managing staff; and the finance organization follows “generally accepted accounting principles” to handle managing the company’s fixed and financial assets. Unfortunately, what we don’t have is a set of generally accepted principles for data. This is what data governance establishes.
The reason that you see the term process in nearly every definition of data governance is that until you establish and standardize data related processes, you’ll never get any of the work done. Getting started with data governance isn’t about establishing a committee – it’s about identifying the goals and identifying the policies and processes that will direct the work activities. You can’t be successful in managing an asset if everyone has their own rules and methods for accessing, manipulating, and using the asset. This isn’t rocket science – geez – the world of ERP implementations and even business reengineering projects learned this concept more than 10 years ago.
The reason to manage data as a corporate asset is to ensure that business activities that require data are able to use and access data in a simple, uniform, consistent manner. Unfortunately, in the era of search engines, content indexing, data warehouses, and the Cloud, finding and acquiring data to support a new business need can be painful, time consuming, and expensive. Everyone has their own terms, their own private data stash, and their own rules dictating who is and isn’t allowed to access data. This isn’t corporate asset management– this is corporate asset chaos. A data governance initiative is one of the best ways to get started in managing data as a corporate asset.
The Flaw of the Data Inventory

Back when I was applying to college, I’d read over college catalogs. Inevitably, each university would mention the number of books it had in its library. When I finally went to college, I realized that this metric was fairly meaningless. A dozen volumes on Grecian pottery did me no good when I was in search of a book on polymers for my mechanical engineering class.
Clients will often ask us to scope a “data inventory” project, inevitably focused on identifying and describing all the data elements contained across their different application systems. Recently a new CIO asked us to head up a “tiger team” to inventory his company’s data. He was surprised at the quantity of information needs that had been sent his way. As expected, he inquired about systems of record and data dictionaries. As you can imagine, he received multiple and conflicting answers which only exacerbated his confusion.
As a point of reference, well-known ERP systems can have in excess of 50,000 discrete data elements in their databases (never mind that some aren’t in English). As I’ve written in the past, many of these data elements have no use outside of the application itself.
Having terabyte upon terabyte of information is equally irrelevant if that data is unrelated to current business issues. The problem with a data inventory activity is that identifying and counting data elements in different systems and applications won’t necessarily solve any problems. Why? Because data across applications and packages is inconsistent: there are different names, definitions, and values, and there is no practical means of determining which data they actually have in common. This is like going to the hardware store and looking for a specific screw, but all the different screws are in one big barrel—you end up having to pick through each screw, one at time. When you find the screw, you just throw all the other screws back into the barrel.
The point of a data inventory isn’t to pick through data because it exists, but to inventory the data people actually need. If you’re going to undertake a data inventory, your output should be structured so that the next person doesn’t have to repeat your work. Identify the data that is moving across various systems, as this indicates key information that’s being shared. Categorize this data by subject area. You’ll inevitably find that there are inconsistent versions of the data, enabling you to identify data disparities. You can then begin to develop a catalog of key corporate data that will form the basis of your data dictionary.
Inventorying the data that moves between systems accomplishes two things: it identifies the most valuable data elements in use, and it will also help identify data that’s not high-value, as it’s not being shared or used. This approach also provides a way to tackle initial data quality efforts by identifying the most “active” data used by the business. It ultimately helps the data management team understand where to focus its efforts, and prioritize accordingly.
So next time someone suggests a data inventory without context or objectives, consider sending them to college to study Grecian urns.
Not MDM, Not Data Governance: Data Management.

Has everyone forgotten database development fundamentals?
In the hubbub of MDM and data governance, everyone’s lost track of the necessity of data standards and practices. All too often when my team and I get involved with a data warehouse review or BI scorecard project, we confront inconsistent column names in tables, meaningless table names, and different representations of the same database object. It’s as though the concepts of naming conventions and value standards never existed.
And now the master data millennium has begun! Every Tom, Dick, and Harry in the software world is espousing the benefits of their software to support MDM. “We can store your reference list!” they say. “We can ensure that all values conform to the same rules!” “Look, every application tied to this database will use the same names!”
Unfortunately this isn’t master data management. It’s what people should have been doing all along, and it’s establishing data standards. It’s called data management.
It’s not sexy, it’s not business alignment, and it doesn’t require a lot of meetings. It’s not data governance. Instead, it’s the day-to-day management of detailed data, including the dirty work of establishing standards. Standardizing terms, values, and definitions means that as we move data around and between systems it’s consistent and meaningful. This is Information Technology 101. You can’t go to IT 301—jeez, you can’t graduate!—without data management. It’s just one of those fundamentals.
SOA Mandates Data Management
By Evan Levy
I've always said that the focus on SOA is too much on the "A" for "architecture." The whole idea of SOA is to define application functions and services that need to be accessible to other systems. Prior to SOA, it was always hairy to move data from one system to another.
But everyone thinks that SOA is an integration framework. In fact it's a means of remotely accessing other systems and their related information without having to know the details. For instance, I don't need to know how my cell phone number was assigned; I just need to remember that number so I can share it with my friends.
As I've said before, SOA is the evolutionary result of all the middleware companies trying to convince us to buy their hardware-independent products. SOA's ability to business flexibility today is just as remote as the code objects of decade ago promising to make business more nimble. SOA isn't a business term. It's a technical term for technical people to focus on re-use, standard parts, and standardized processes.

Companies turning to SOA are looking for the holy grail. Consider the emergence of the term "SOA governance" to address the conundrum of SOA development planning. The core issue is how to simplify developers' work in building applications without having to understand the technical details and obstacles in between. Just because I have advanced features and functions doesn't mean I don't still have to focus on software development fundamentals. Design reviews, code re-use, and development standards still matter.
The real challenge with implementing any kind of web service, or defining services that can be re-used, is in ensuring that the data they are dependent on is well-defined. Unfortunately there is no such thing as a business process that is data-independent. Until you've standardized your data, which means implementing data management and maintaining data in a sustainable way, you can't have re-usable services. Period.
