
Data Strategy Component: Identify
Based on the feedback and questions I’ve received on last week’s blog, “The 5 Components of a Data Strategy”, I thought I’d spend a bit more time discussing the individual components along with some of their associated details (or facets). I’ll review each of the five components over the next few weeks. This week, I’ll focus on Identify.
The definition of Identify is:
“The ability to identify data and understand its meaning regardless of its structure, origin, or location”
Identify encompasses how you reference and represent a particular piece of information. This component is probably the most fundamental component of all 5. If you don’t know what something is called, how can you use it, reference it, analyze it, or even share it?
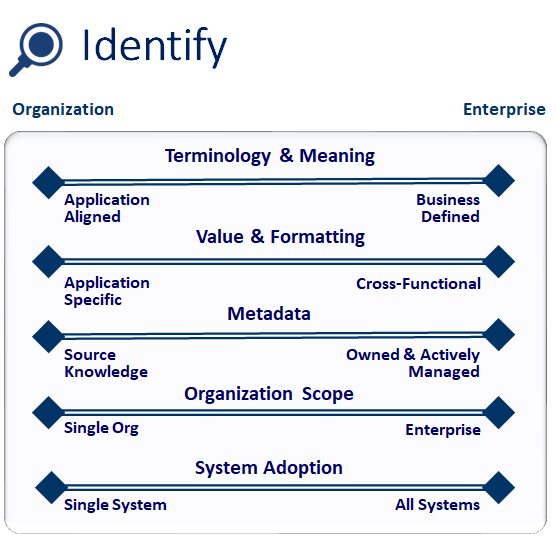
You’ll notice 5 facets (or subcomponents) in the illustration associated with the Identify component (technology & meaning, value & formatting, metadata, organization scope, and system adoption). These facets provide a lower level of detail to analyze and address the specific needs of your environment and the associated Data Strategy. It’s not uncommon to have more than 5 core facets; facet identification is based on the quantity and details of your data strategy goals. I’ve identified 5 of the most common facets that I’ve seen while working with clients.
In addressing the data needs and challenges that exist in your environment, it’s valuable to understand if the ultimate solution requires an enterprise approach or can be addressed with an organizationally-centric approach. An organizational approach focuses on the terminology and details specific to an individual organization and assumes that the data isn’t shared or distributed outside the boundaries of an organization. An enterprise approach assumes that data is distributed across multiple organizations, so the rigor and effort involved is more time-consuming and complex. Part of developing a Data Strategy is to understand the level of sophistication necessary to share data across the appropriate audiences.
Terminology & Meaning
This is the most common challenge with data usage in companies. Are business terms used consistently, or do staff members (and reports) refer to business information with different names? The objective is to establish consistent business terminology for the audience that shares the information. It’s also important to be able to differentiate business concepts that use the same term, but have a different meaning.
Value & Formatting
This facet is the simplest, the most frequently ignored, and (I think) the most aggravating. The idea is to establish the format of a business term’s values. A simple example is identifying the state value in an address. Is the value represented as the 2-character abbreviation or the full name (or the ANSI code)? While not complicated, this facet can present an enormous obstacle in using data if such details are not well understood.
Metadata
Metadata is descriptive information about data (e.g. definition, source of creation, date of creation, valid values, etc.) In the world of business information, everyone agrees that metadata content is critical to using and sharing information. Does your company create, collect, and/or publish metadata about business information? The goal of metadata is not about building exhaustive, perfect, and up-to-date content, it’s about identifying what’s necessary to support usage and sharing (in a practical and time effective manner).
Organization Scope
This facet focuses on the breadth of audience that is associated with the Data Strategy. Does your company require organizations to share data, or is the disparity of operations prevent the need for sharing and distributing data across the enterprise? Organization scope identifies the different organizations that will become stakeholders and participants in the Data Strategy effort.
System Adoption
This facet is often neglected because there’s an assumption that all systems should any new rules and policies. While forcing all systems to adopt new data standards seems appropriate, it may be unrealistic in practice. If your company’s core application systems are packaged applications, there may be limitations to changing code to reflect standard names, terms, and values. You might find that your Data Strategy recommendations are applicable to all systems, or be limited to shared data sets and reporting data repositories.
To be fair, there are other characteristics that can be associated with this component; I’ve just identified 5 of the most popular. When I work with clients, it’s not uncommon to identify 10 or more characteristics of a component. It’s really about identifying the core characteristics (aspects) that are causing obstacles within your business environment and deciding which ones to focus on and improve.
MDM: Build or Buy?

On the publication of my new Informatica white paper, titled “Master Data Management: Building a Foundation for Success,” I’ve been talking to several clients and vendors wanting more information about the build-versus-buy decision. In fact when I was writing the paper I was in the process of evaluating three MDM vendor solutions on behalf of a high-technology firm we work with, while at the same time counseling another firm not to jump too quickly into the MDM fray without first examining its incumbent technology solutions. As with most strategic IT solutions, when it comes to MDM one size doesn’t fit all.
As I say in my Informatica paper, there are a variety of factors involved in the rigorous evaluation of MDM technology. In the paper, I describe five core MDM functions that should drive a deliberate MDM strategy:
- Data cleansing and correction
- Metadata
- Security and access services
- Data migration
- Identity resolution
Interestingly, each of these core functional areas can exist on its own, absent any sort of MDM solution or plan. You probably have a few of them already.
Which is why it amazes me that so few companies actually take a structured and proactive approach to planning their MDM initiatives. Why go through a business-driven process of examining the importance of, say, matching, when it’s easy enough to let the vendor make its pitch and start negotiating prices? Because you can end up overinvesting, that’s why.
We worked with a large media company on a set of robust MDM business and functional requirements back in 2007. The goal was to prioritize MDM requirements and then map them to various vendor capabilities. This would ensure that the resulting solution solved the right business issues. We delivered our MDM Masterplan to the client, and MDM immediately got funding. Success!
But management at the media company got sucked into the hype of a rival media company’s MDM success, and ended up choosing the same vendor as its competitor. Flash forward to 2009. The media company continues to implement and customize its MDM solution, with no rollout date in sight.
The point here is whether you choose to build or buy your MDM solution, know what you need, and what you don’t need. I know that sounds obvious. But obviously, it’s not.
photo by Guwashi999 via Flickr (Creative Commons License)
Not MDM, Not Data Governance: Data Management.

Has everyone forgotten database development fundamentals?
In the hubbub of MDM and data governance, everyone’s lost track of the necessity of data standards and practices. All too often when my team and I get involved with a data warehouse review or BI scorecard project, we confront inconsistent column names in tables, meaningless table names, and different representations of the same database object. It’s as though the concepts of naming conventions and value standards never existed.
And now the master data millennium has begun! Every Tom, Dick, and Harry in the software world is espousing the benefits of their software to support MDM. “We can store your reference list!” they say. “We can ensure that all values conform to the same rules!” “Look, every application tied to this database will use the same names!”
Unfortunately this isn’t master data management. It’s what people should have been doing all along, and it’s establishing data standards. It’s called data management.
It’s not sexy, it’s not business alignment, and it doesn’t require a lot of meetings. It’s not data governance. Instead, it’s the day-to-day management of detailed data, including the dirty work of establishing standards. Standardizing terms, values, and definitions means that as we move data around and between systems it’s consistent and meaningful. This is Information Technology 101. You can’t go to IT 301—jeez, you can’t graduate!—without data management. It’s just one of those fundamentals.
The Flaw of the Hub-and-Spoke Architecture
By Evan Levy
I recently talked to a client who was fixated on a hub-and-spoke solution to support his company’s analytical applications. This guy had been around the block a few times and had some pretty set paradigms about how BI should work. In the world of software and data, the one thing I’ve learned is that there are no absolutes. And there’s no such thing as a universal architecture.

The premise of a hub-and-spoke architecture is to have a data warehouse function as the clearing house for all the data a company’s applications might need. This can be a reasonable approach if data requirements are well-defined, predictable, and homogenous across the applications—and if data latency isn’t an issue.
First-generation data warehouses were originally built as reporting systems. But people quickly recognized the need for data provisioning (e.g., moving data between systems), and data warehouses morphed into storehouses for analytic data. This was out of necessity: developers didn’t have the knowledge or skills to retrieve data from operational systems. The data warehouse was rendered a data provisioning platform not because of architectural elegance but due to resource and skills limitations.
(And let’s not forget that the data contained in all these operational systems was rarely documented, whereas data in the warehouse was often supported by robust metadata.)
If everyone’s needs are homogenous and well-defined, using the data warehouse for data provisioning is just fine. The flaw of hub-and-spoke is that it doesn’t address issues of timeliness and latency. After all, if it could why are programmers still writing custom code for data provisioning?
When an airline wants to adjust the cost of seats, it can’t formulate new pricing based on old data—it needs up-to-the-minute pricing details. Large distribution networks, like retailing and shipping, have learned that hub-and-spoke systems are not the most efficient or cost-effective models.
Nowadays most cutting-edge analytic tools are focused on allowing the business to quickly respond to events and circumstances. And most companies have adopted packaged applications for their core financial and operations. Unlike the proprietary systems of the past, these applications are in fact well-documented, and many come with utilities and standard extracts as part of initial delivery. What’s changed in the last 15 years is that operational applications are now built to share data. And most differentiating business processes require direct source system access.
Many high-value business needs require fine-grained, non-enterprise data. To move this specialized, business function-centric content through a hub-and-spoke network designed to support large-volume, generalized data is not only inefficient but more costly. Analytic users don’t always need the same data. Moreover, these users now know where the data is, so time-sensitive information can be available on-demand.
The logistics and shipping industries learned that you can start with a hub-and-spoke design, but when volume reaches critical mass, direct source-to-destination links are more efficient, and more profitable. (If this wasn’t the case, there would be no such thing as the non-stop flight.) When business requirements are specialized and high-value (e.g., low-latency, limited content), provisioning data directly from the source system is not only justified, it’s probably the most efficient solution.
